
 How many “Million Dollar” ideas do you have? I bet you have some good ones – I think we all do. I will also guess that none them have resulted in you having $1M (and I hope I am wrong.) Don’t worry, you are in good company. I recently decided the likelihood of me implementing any of my “million dollar” ideas is quickly diminishing. We are all probably familiar with the quote, “Talent is 1% inspiration and 99% perspiration.” I perspire a lot, but unfortunately it is rarely in pursuit of my “strokes of genius.” So I have decided to share one of my ideas, an idea that any university interested in improving student success could implement and discover a marked improvement.
How many “Million Dollar” ideas do you have? I bet you have some good ones – I think we all do. I will also guess that none them have resulted in you having $1M (and I hope I am wrong.) Don’t worry, you are in good company. I recently decided the likelihood of me implementing any of my “million dollar” ideas is quickly diminishing. We are all probably familiar with the quote, “Talent is 1% inspiration and 99% perspiration.” I perspire a lot, but unfortunately it is rarely in pursuit of my “strokes of genius.” So I have decided to share one of my ideas, an idea that any university interested in improving student success could implement and discover a marked improvement.
What do your online shopping, your medical records, your social media likes, and your GPS wayfinder app all share in common? The answer – they all use data to analyze problems, improve decision making, save money, and maximize customer satisfaction. The ability to collect and use data is growing exponentially this century. For example, recently, my 11 year old was mocking an electronic device that has only 1 gigabyte (GB) of storage. I thought a gigabyte sounded like a lot. Remember 5’1/4” floppy disks? They held at the most one megabyte. Today there are terabytes (1,000 GBs), petabytes (1M GBs), and exabytes (100M GBs).
 With the power of today’s computers, millions, if not billions, of data points can be quickly analyzed for trends, patterns, and projections. For the past three decades, I have been in the “business” of using data to predict college student retention. The benefits of student success are many and most importantly (to me) are transformed lives. However, from a purely return on investment perspective, many respected college success scholars (Noel, Levitz, Tinto, Schuh) suggest that since it takes three to five times the amount of money to recruit a student versus retain a student in college, we could save a lot of money if we focus more on the latter. Student retention and graduation data have also increased to 35% of some formulas (U.S. New) for ranking universities.
With the power of today’s computers, millions, if not billions, of data points can be quickly analyzed for trends, patterns, and projections. For the past three decades, I have been in the “business” of using data to predict college student retention. The benefits of student success are many and most importantly (to me) are transformed lives. However, from a purely return on investment perspective, many respected college success scholars (Noel, Levitz, Tinto, Schuh) suggest that since it takes three to five times the amount of money to recruit a student versus retain a student in college, we could save a lot of money if we focus more on the latter. Student retention and graduation data have also increased to 35% of some formulas (U.S. New) for ranking universities.
An entire industry has risen outside of universities to help them improve student retention and graduation rates. Companies like the Education Advisory Board (EAB), Civitas , Skyfactor, and Pharos have been emerging and expanding their services over the past decade. The profitability of this type of company service was demonstrated in 2017 when EAB sold for $1.5 billion dollars.
As is the case with most great companies, they need to protect their competitive advantages. In many cases this is the “secret sauce” they use to predict student success. However, having learned more about these various predictive models, I am confident that they are leaving out essential data that could significantly improve their models’ predictability.
This is by no means an intentional mistake by these companies and universities. It basically comes down to the inability to study what we don’t know how to measure. The result in what I call the Missing Data Model which calculates student predictive success without accounting for the wider array of factors that can improve our estimates. The “missing” data is the inability of universities (and student success companies) to figure out how to capture and use a large number of student engagement indicators literally all across campus.
success without accounting for the wider array of factors that can improve our estimates. The “missing” data is the inability of universities (and student success companies) to figure out how to capture and use a large number of student engagement indicators literally all across campus.
My Missing Data Model is rooted in a quick return to theory, instead of practice. Almost every retention theory I have studied is based on a combination of academic and social measures. Tinto wrote about the integration of the academic and social lives of the student. Pascarello’s model was based primarily on student interaction with faculty and student interaction with each other. Astin’s I-E-O model (Inputs-Environment-Outcomes) described the Environment component as interactions with faculty and interactions with students and student groups.
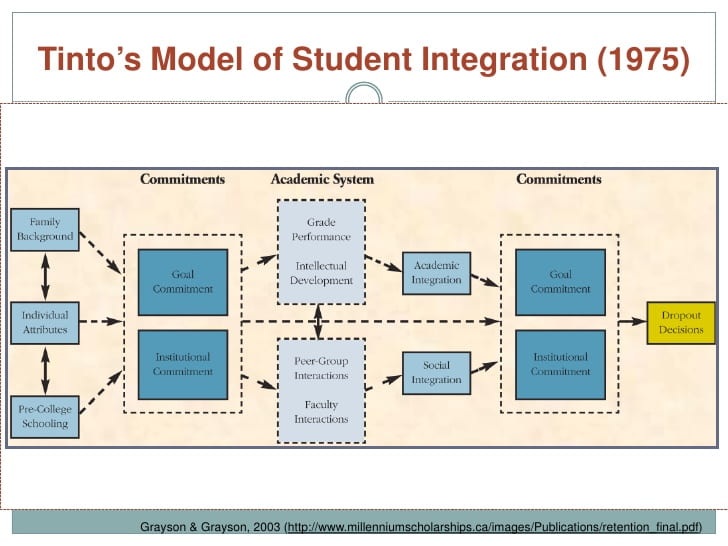 The challenge in implementing any of these theories on a campus is that quantitative retention projections can only be based on the available data, and that numerical data is almost always represents only half of this model – the academic side. Academic data is abundant in part because 1) it is used to demonstrate competence for admission to college, and 2) high schools are expected to demonstrate positive outcomes in order to maintain and/or improve state funding. Some of these academic variables include high school grade point average, standardized test scores, high school rank, high school rigor, advanced placement credits, national academic awards, etc.
The challenge in implementing any of these theories on a campus is that quantitative retention projections can only be based on the available data, and that numerical data is almost always represents only half of this model – the academic side. Academic data is abundant in part because 1) it is used to demonstrate competence for admission to college, and 2) high schools are expected to demonstrate positive outcomes in order to maintain and/or improve state funding. Some of these academic variables include high school grade point average, standardized test scores, high school rank, high school rigor, advanced placement credits, national academic awards, etc.
Once students begin the lived experience of college, the number of factors that can be used for student success prediction continues in with this academic theme. Examples include: college GPA, credits attempted vs. credits earned, number of D/F grades, choice of major, etc. One company’s formula for student success at Baylor reports that the following five factors are needed, along with some pre-matriculation variables:
- GPA
- Semesters completed
- Transfer credits
- Attempted credits/term
- D/F grades
When I asked this company why the only predictive factors they used were academic data that were somewhat easy to obtain, they explained that they did not incorporate non-academic factors in their model because:
- there was not enough research in student success research to indicate what these factors might be,
- there were not enough universities collecting non-academic data, and therefore, it wouldn’t make sense to base a model on data that only a few colleges had gathered.
Honestly, this makes complete sense. Use the data that everyone already has. However, in this case, my colleagues and I decided to compare this company’s student success predictive model to a model we had developed which incorporated student engagement outside the classroom. We discovered that when we included these non-academic variables that the retention predictions were significantly improved and more actionable than the company’s existing student success model. Some of these variables included:
- Students’ sense of belonging
- Students’ sense of stress
- Students’ feeling that at least one faculty/staff member cared about them
- Students’ comfort with how their next semester’s bill would be paid
- Students’ who saw their culture represented on campus
- Students’ who thought about going home much of the time
- Students’ number of work hours
- Students’ attendance at an optional extended orientation experience
While these variables strengthened our ability to predict retention, they were not easily gathered. They were dependent on the results of a ~30 item survey that necessitated that university housing spent hundreds of hours working to secure a 90% response rate from first year students.
The point, however, is that there are non-academic variables, other than the easily obtained academic measures, that can be used to better predict retention. If a university does not want to make the effort to collect survey data on students early in their first semester, the challenge is to identify what other non-academic measures are available that are not on anyone’s radar.
This can be more difficult for many student affairs staff because traditionally, the majority of student affairs staff are more relationally than task focused. I’m not saying this relational approach is not important – I would argue it is essential to student success, especially when the faculty reward system is based on publications and teaching, not outside the class student interaction. Most student affairs and other student success departments serve as an effective counter-weight to the level of academic challenge faculty typically provide in the classroom (Sanford, 1962).
majority of student affairs staff are more relationally than task focused. I’m not saying this relational approach is not important – I would argue it is essential to student success, especially when the faculty reward system is based on publications and teaching, not outside the class student interaction. Most student affairs and other student success departments serve as an effective counter-weight to the level of academic challenge faculty typically provide in the classroom (Sanford, 1962).
I share this about student affairs staff, having worked with and among them for multiple decades, because I have found myself an anomaly among many of them. My pre-student affairs background was focused on math and science (which believe it or not, I honestly enjoyed,) until I realized that I had few, if any, meaningful friendships or connections in college. When I discovered student engagements outside the classroom, my college experience (and life) were transformed and led me down an entirely new path.
As I transitioned my career to student affairs, I noticed how little quantitative data was being used in student success. Over the past 25 years, I have been able to focus on better planning, implementing, assessing and improving the design, system, and structure of the student affairs areas where I worked.
Enough about me. What I would like to share next is referred to as a “million dollar” idea because if universities started to collect this data, they would undoubtably increase student success, retention, grades, and graduation rates, which in turn would save them millions of dollars. Sadly, what you will likely discover is that few, if any colleges are collecting, tracking, and analyzing this data. Some of th e data is literally low-hanging fruit, ripe for the picking, while other examples are more intrusive measures that would require deeper reflection on the benefits and drawbacks on collecting this data.
e data is literally low-hanging fruit, ripe for the picking, while other examples are more intrusive measures that would require deeper reflection on the benefits and drawbacks on collecting this data.
However, if you, your university, and/or your company want to set a standard for excellence in student success, you will begin to have conversations about how some of this data might be gathered and used. The accompanying list of student out-of-class engagements that follow offer a range of opportunities for data that, if collected, will provide a much more complete picture of our students and ultimately result in improved student success.
You are encouraged to share these ideas with your colleagues and ask them how the next steps might be taken. If you want additional help and insight on this topic, I will be happy to talk to you also.
Examples of the missing data which could be better predict student success is included in the post “Missing Data from Student Engagement that Can Improve Student Success”.
